
Introduction
In the fast-paced world of digital information, data scraping has become an essential tool for businesses, researchers, and developers alike. Imagine being able to extract valuable insights from a sea of online data at the click of a button—sounds like a dream, right? However, this dream can quickly turn into a nightmare if the website you’re targeting isn’t structured wisely. The truth is, the design and architecture of a website play a pivotal role in the success of your data scraping projects. A well-organized site can make your job significantly easier, while a poorly structured one can lead to headaches, frustration, and wasted resources. In this article, we’ll dive into how website structures impact the effectiveness of data scraping efforts and why understanding these elements is crucial for achieving your data goals. So, whether you’re a seasoned pro or just starting your data journey, let’s explore how to navigate the complexities of web architecture to maximize your scraping success!
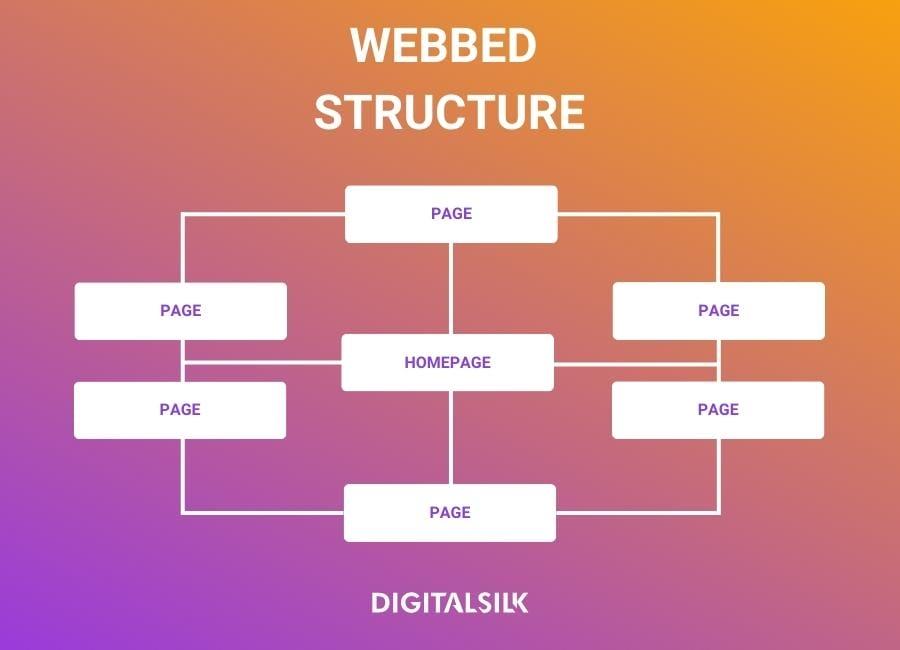
Understanding the Importance of Website Hierarchy in Data Scraping Success
The structure of a website plays a pivotal role in shaping the effectiveness of data scraping projects. When a site is well-organized, it not only enhances user experience but also significantly eases the scraping process. A clear hierarchy enables scrapers to navigate the content efficiently, thereby improving the accuracy and speed of data extraction.
One of the key aspects of website hierarchy is the URL structure. Well-defined URLs that reflect the content hierarchy facilitate easier scraping. For example, a URL like www.example.com/products/electronics/phones gives immediate context about what data to expect. In contrast, a chaotic URL structure can lead to confusion and wasted resources. To highlight the importance:
- Consistent Naming Conventions: Ensures that similar pages can be predicted and scraped with minimal adjustments.
- Subcategories: Allows extractors to focus on specific areas without sifting through irrelevant data.
- Breadcrumb Navigation: Helps identify the parent and child relationships of pages, further aiding in targeted scraping.
Moreover, the HTML structure of a page—such as headings, tags, and classes—also influences scraping success. Effective use of semantic HTML ensures that the content is more accessible to scrapers. For instance, using
for primary titles and
| HTML Structure | Impact on Scraping |
|---|---|
Main Title | Defines the primary focus of the page. |
Subheading | Organizes content into clear sections. |
Content | Helps scrapers locate specific data easily. |
In addition to structural elements, the internal linking strategy of a website is crucial. A well-planned internal linking system not only boosts SEO but also guides scrapers through the content maze. By linking relevant pages, you ensure that the scraper doesn’t miss any vital information. Internal links create an interconnected web that enhances both user navigation and data extraction.
Ultimately, understanding and optimizing website hierarchy is not just a technical consideration; it’s a strategic advantage in data scraping. When websites prioritize clear structures and semantic HTML, they empower scrapers to perform with greater effectiveness, leading to richer data sets and more successful scraping outcomes. Investing time in establishing a robust website hierarchy can yield significant returns, simplifying the scraping process and enhancing overall project efficiency.
Identifying Key Elements of a Website Structure for Effective Scraping
Understanding the architecture of a website is essential for any data scraping project. A well-structured website not only enhances user experience but also significantly influences the efficiency of scraping efforts. When identifying the key elements of a website’s structure, focus on the following aspects:
- URL Patterns: Examine how URLs are formatted. Consistent, predictable URL patterns can simplify the process of navigating and extracting data.
- HTML Markup: Pay attention to the semantic structure of the HTML. Proper use of headings, lists, and tables can make it easier to isolate relevant content.
- CSS Selectors: Identifying unique classes or IDs can streamline the scraping process, allowing you to target specific elements without unnecessary complexity.
- JavaScript Dependencies: Many modern websites rely on JavaScript to load content. Understanding how these scripts operate can help you determine whether you’ll need to simulate a browser environment.
- API Availability: Sometimes, the data you want is available through an API. Identifying these endpoints can save time and resources compared to scraping HTML.
Additionally, using a structured approach to analyze the data flow can make a significant difference. When mapping out the site, consider creating a flowchart to visualize how information is organized and interlinked. This can help you identify:
| Element | Importance | Impact on Scraping |
|---|---|---|
| Navigation Menus | High | Guides the scraper to different content sections. |
| Content Blocks | Medium | Directly relates to the data to be scraped. |
| Pagination | High | Affects data completeness across multiple pages. |
Remember that some sites may implement measures to hinder scraping efforts, such as CAPTCHAs or IP blocking. Being aware of these challenges and understanding the site’s structure can help you devise strategies to navigate around them. For instance, if a website uses dynamic loading, you might need to use tools that can handle asynchronous requests.
Ultimately, a thorough understanding of key structural elements will not only increase the success rate of your scraping project but also save valuable time and resources. By investing in the analysis of a website’s architecture upfront, you can embark on a more efficient and effective data extraction journey.
How Navigation Menus Influence Data Accessibility and Quality
When it comes to data scraping, the layout and design of a website’s navigation menus can significantly impact the ease with which data is accessed and extracted. A well-structured navigation system not only enhances user experience but also guides data scraping tools to locate and interpret information more effectively.
Consider the following advantages of organized navigation menus:
- Clear Hierarchy: A logical hierarchy allows scrapers to follow a predictable path, making it easier to locate valuable data. When information is categorized effectively, scraping tools can efficiently target specific sections of the site.
- Consistent Labeling: Uniform terminology across navigation links helps scrapers recognize patterns and understand the context of the data they are extracting. This consistency reduces errors during data collection.
- Reduced Redundancy: A streamlined menu minimizes duplicate links and sections, which can lead to confusion and unnecessary data duplication in scraping results.
Moreover, the design choices—such as dropdowns, mega menus, and sidebar navigation—play a crucial role. For instance, a mega menu can present a vast amount of information at a glance without cluttering the page, but it can also complicate scraping if not implemented thoughtfully. Here’s a quick comparison of navigation types and their impact on data scraping:
| Navigation Type | Data Accessibility | Scraping Complexity |
|---|---|---|
| Dropdown Menus | Moderate | High |
| Mega Menus | High | Moderate |
| Sidebar Navigation | High | Low |
Additionally, navigation menus serve as a roadmap for web crawlers, allowing for efficient indexing of website content. When a site’s structure is intuitive, search engine bots can easily traverse the site, enhancing the overall visibility and accessibility of data. This inherent visibility not only benefits human users but also ensures that scraping efforts yield quality results.
Ultimately, the interplay between navigation menus and data scraping reveals the importance of thoughtful web design. By prioritizing user-friendly navigation, webmasters can improve both user experience and the effectiveness of scraping projects. This dual benefit highlights a fundamental principle: good website architecture is not just about aesthetics; it’s a critical component of data accessibility and quality.

The Role of URL Patterns in Streamlining Your Scraping Strategy
Understanding URL patterns is crucial for anyone looking to enhance their web scraping efforts. These patterns serve as a roadmap, guiding your scraper through the vast landscape of a website. By recognizing how URLs are structured, you can significantly reduce the time spent on configuring your scraping tools and increase the efficiency of your data extraction process.
Websites often utilize consistent URL structures that can be categorized based on:
- Static URLs: These URLs remain the same and typically represent fixed resources. Examples include homepage links or product pages.
- Dynamic URLs: These URLs change based on parameters such as search queries or filters. They often include question marks and ampersands, which can be complex to navigate.
- Hierarchical Structures: Many sites employ a systematic hierarchy in their URLs, which reflects the content organization, making it easier to predict additional resources.
By identifying these patterns, you can tailor your scraping strategy accordingly. For instance, if a website uses a pattern like example.com/category/itemID, you can easily construct a list of URLs to scrape by simply changing the itemID. This approach not only saves time but also minimizes the load on the server, as you can efficiently collect data without making excessive requests.
Moreover, employing tools that automatically detect and adapt to URL patterns can streamline your scraping projects further. Many modern scraping frameworks come equipped with features that allow you to define rules based on patterns, facilitating the detection of related pages and resources. This capability can be a game-changer for large-scale scraping tasks.
To illustrate the impact of URL patterns, consider the following table comparing two websites with different URL structures:
| Website | URL Structure | Scraping Strategy |
|---|---|---|
| Website A | example.com/products/item1 | Static URL scraping |
| Website B | example.com/products?category=shoes&page=2 | Dynamic URL handling with pagination |
By leveraging the insights gained from understanding URL patterns, you can create a robust scraping strategy that adapts to various website architectures. This not only enhances the efficiency of your scraping tasks but also improves the accuracy and relevance of the data collected, ultimately making your projects more successful.

Maximizing Data Collection with Well-Organized HTML Layouts
In the ever-evolving landscape of data scraping, the importance of a well-structured HTML layout cannot be overstated. When websites are organized with thoughtful HTML semantics, it allows scraping tools to extract information efficiently and accurately. This not only saves time but also minimizes errors, leading to more reliable data for analysis.
Consider these key attributes of an effective HTML layout:
- Semantic Tags: Using elements like
, andhelps define content sections clearly. - Consistent Class Naming: Adopting a standard naming convention for classes allows scraping scripts to navigate the DOM more intuitively.
- Nested Structures: Properly nested elements, such as lists within lists, can provide contextual hierarchy that aids data extraction.
- Minimized Dynamic Content: Reducing the use of JavaScript for displaying essential data eases the scraping process, as many tools struggle with dynamically loaded content.
Moreover, optimizing the accessibility of data through structured layouts can enhance the user experience while simultaneously facilitating data scraping. When information is easily accessible to users, it usually reflects a layout that is equally easy for bots to navigate. This dual advantage can be crucial for projects requiring large-scale data collection.
| Benefit | Description |
|---|---|
| Efficiency | Well-structured HTML allows for quicker data retrieval. |
| Accuracy | Minimized errors in data extraction lead to more reliable results. |
| Scalability | Easier to adapt scraping tools for future updates in website structure. |
Ultimately, the success of data scraping projects hinges on the foundational aspects of a website’s HTML structure. By prioritizing organization and clarity in design, webmasters can not only enhance user engagement but also create an environment where data scraping can thrive. Investing time in crafting well-organized layouts is a strategic move that pays dividends in effective data collection.

Dealing with Dynamic Content: Tips for Scraping JavaScript-Heavy Sites
When it comes to scraping data from JavaScript-heavy sites, the traditional methods of web scraping often fall flat. These websites load content dynamically, meaning that the data is not available in the initial HTML source. To successfully extract the information you need, you’ll have to employ a few advanced techniques and strategies. Here are some invaluable tips to enhance your scraping endeavors.
First and foremost, utilize headless browsers. Tools like Puppeteer or Selenium simulate a real browser environment, allowing you to interact with the page just like a human user would. This means you can wait for elements to load and scrape data once it becomes visible. Here’s why headless browsers are a game changer:
- Interactivity: They can handle user interactions like clicks and form submissions.
- Timing: You can set delays to ensure content is fully loaded before scraping.
- JavaScript Execution: They execute JavaScript, rendering the page completely before you pull any data.
Another effective approach involves using APIs when available. Many JavaScript-heavy sites often use APIs in the background to fetch data. By inspecting network requests in your browser’s developer tools, you might find direct API endpoints that return data in a more structured format, such as JSON. Here’s how to identify and utilize these endpoints:
- Inspect Network Activity: Use the ‘Network’ tab to monitor requests made when a page loads.
- Look for AJAX Calls: Identify XMLHttpRequests that pull in data for the page.
- Access Directly: Make requests to these APIs for a straightforward way to retrieve your data.
Furthermore, consider using a scraping framework that is specifically designed to handle dynamic content. Frameworks like Scrapy have built-in support for JavaScript rendering when paired with Selenium or Splash. This can streamline your scraping process and help manage complex tasks effectively. Below is a comparison of some frameworks that can handle JavaScript-heavy sites:
| Framework | JavaScript Support | Ease of Use |
|---|---|---|
| Selenium | Yes | Moderate |
| Puppeteer | Yes | Easy |
| Scrapy with Splash | Yes | Advanced |
| Beautiful Soup | No | Easy |
Lastly, remember to respect the site’s robots.txt file and terms of service. Always check the site’s policies on data scraping, as violating them may lead to being blocked or even facing legal actions. Following ethical scraping practices not only protects you but also contributes to a more sustainable web scraping environment.

Strategies for Overcoming Common Structural Challenges in Data Scraping
Overcoming structural challenges in data scraping requires a blend of technical know-how and strategic foresight. Here are some effective strategies that can help you navigate these common hurdles:
- Understand the HTML Structure: Before diving into scraping, take time to analyze the website’s HTML. Use tools like Inspect Element to identify patterns in the markup. Recognizing how data is structured can save you from unnecessary headaches later on.
- Utilize CSS Selectors: Leverage the power of CSS selectors to target specific elements on a page. This approach can simplify the scraping process significantly. By refining your selectors, you can extract only the data you need without capturing irrelevant information.
- Implement Pagination Handling: Many websites employ pagination to manage large datasets. Ensure your scraper can navigate through multiple pages effectively. Consider using automation tools that can mimic user behavior, allowing you to scrape data from all pages without manual intervention.
- Handle Dynamic Content: Websites that rely on JavaScript to load data can pose a challenge. Tools such as Selenium or Puppeteer can help you interact with these dynamic elements, allowing you to extract data that isn’t readily available in the initial HTML response.
- Monitor for Changes: Websites often undergo structural changes that can break your scraping logic. Set up alerts to notify you of changes in the data structure. Regularly updating your scraping scripts ensures continued success and minimizes downtime.
| Challenge | Strategy |
|---|---|
| HTML Structure Complexity | Thorough analysis and pattern recognition |
| Dynamic Content Loading | Use automation tools like Selenium |
| Pagination | Implement automated page navigation |
| Frequent Layout Changes | Set up monitoring and alerts |
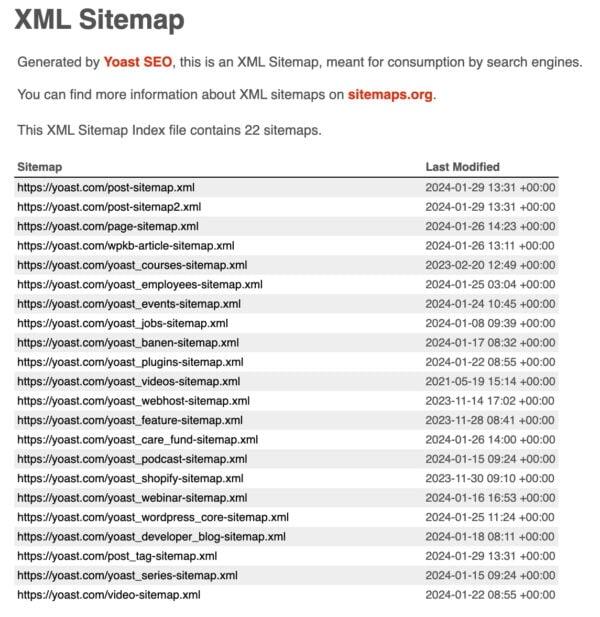
Leveraging Sitemaps to Enhance Your Data Scraping Projects
When it comes to data scraping, understanding the structure of a website is crucial. One of the most effective tools at your disposal is a sitemap. This XML file provides a roadmap of the site’s content, detailing its structure and organization. By leveraging sitemaps, you can significantly enhance the efficiency and accuracy of your data scraping projects. Here’s how:
- Faster Navigation: Sitemaps outline the URLs of a website, allowing your scraping scripts to target specific pages directly. This cuts down on unnecessary navigation through irrelevant content, saving you time and resources.
- Comprehensive Coverage: A well-structured sitemap ensures that no crucial data is overlooked. You can identify all the valuable endpoints, from product pages to blog posts, making it easier to gather the information you need.
- Understanding Priority and Frequency: Sitemaps often indicate how frequently pages are updated and their priority levels. This information can help you prioritize your scraping efforts, focusing on high-value pages that provide the most relevant data.
Additionally, sitemaps help you avoid common pitfalls associated with scraping. Many websites employ measures to block bots, such as CAPTCHAs or complex navigation structures. By analyzing the sitemap, you can develop strategies to bypass these barriers, leading to a more successful scraping experience. For example, knowing which pages are less likely to be monitored for bot activity allows you to scrape those pages first.
Here’s a simple table to highlight the benefits of using sitemaps in your scraping endeavors:
| Benefit | Description |
|---|---|
| Efficiency | Target specific URLs quickly, reducing runtime. |
| Coverage | Ensure all relevant data points are included. |
| Insight | Gain understanding of page importance and updates. |
Moreover, incorporating sitemaps into your scraping workflow can enhance the overall quality of the data collected. With a clearer view of the site’s structure, you can establish a more logical data extraction process, minimizing the chances of errors. By aligning your scraping strategies with the website’s architecture, you enhance not only the effectiveness of your projects but also the accuracy and relevance of the data obtained.

Best Practices for Structuring Your Own Website for Future Scraping Needs
When designing your website with future scraping in mind, the structure you choose can greatly influence the efficiency and effectiveness of your data extraction efforts. A well-organized website not only improves user experience but also makes it easier for crawlers to navigate and collect relevant data. Here are some best practices to consider:
- Use a Consistent URL Structure: Opt for descriptive and meaningful URLs. This makes it easier for scrapers to understand the content and context of each page. For example, use
yourwebsite.com/products/electronics/instead ofyourwebsite.com/page?id=123. - Implement Semantic HTML: Utilize HTML5 to give meaning to your content. Using appropriate semantic elements like
, andhelps scrapers recognize the structure and hierarchy of your information. - Maintain a Clean and Logical Hierarchy: Organize your content hierarchically with clear categories and subcategories. This not only aids users but also allows scrapers to retrieve data efficiently. For example:
| Category | Subcategory | Content Type |
|---|---|---|
| Electronics | Mobile Phones | Product Listings |
| Electronics | Laptops | Product Listings |
| Home Appliances | Refrigerators | Product Listings |
Another critical aspect is the use of metadata and structured data. By implementing schema markup, you provide additional context about your content that scrapers can utilize. Search engines and scraping tools can better understand your data, leading to more accurate and complete extractions.
consider the robots.txt file and your website’s overall accessibility. Ensure that the file allows scrapers to access essential sections of your site while preventing them from indexing non-critical areas. This strategic control can help you manage server load and improve data extraction performance.
The Impact of Responsive Design on Data Extraction Efficiency
Responsive design has revolutionized the way websites are built, fundamentally altering the landscape of data extraction. When a website adapts seamlessly to various screen sizes and devices, it not only enhances user experience but also influences the efficiency of data scraping efforts. The dynamic nature of responsive design introduces both opportunities and challenges for data extraction tools and techniques.
One of the most significant benefits of responsive design is its ability to present consistent data structures across devices. This uniformity is essential for data scraping, allowing tools to identify and extract information with greater accuracy. Consider the following advantages:
- Consistent HTML structure: A stable layout ensures that selectors remain effective, reducing the need for constant adjustments.
- Reduced complexity: Simplified navigation menus and standardized content placement help scrapers navigate through the data swiftly.
- Enhanced accessibility: Responsive sites often prioritize mobile-friendly elements, making it easier for scrapers to access valuable information without encountering barriers.
However, the responsive design can also introduce complexities that data extractors must contend with. For instance, the use of JavaScript frameworks and dynamic loading can obscure critical data points, making them difficult to capture. Here are some common challenges:
- Dynamic content loading: Elements that load asynchronously may require more advanced scraping techniques to ensure all data is captured.
- Variable element placements: Changes in layout across devices can lead to inconsistencies in data retrieval if not properly accounted for.
- Increased need for browser emulation: Some data may only be accessible through simulated user interactions, complicating the extraction process.
To effectively tackle these challenges, it’s crucial for data scrapers to adapt their methodologies. Implementing robust error handling and developing flexible scraping scripts can significantly enhance extraction efficiency. Furthermore, understanding the specific responsive design techniques used by a website can lead to more targeted and efficient scraping strategies. The key lies in leveraging the strengths of responsive design while being prepared to navigate its hurdles.
Frequently Asked Questions (FAQ)
Q&A: How Website Structures Impact the Success of Data Scraping Projects
Q1: What is data scraping, and why is it important for businesses?
A1: Data scraping is the process of automatically extracting information from websites. In today’s data-driven world, businesses rely on scraping to gather insights about market trends, customer behavior, and competitor activities. It’s like having a digital magnifying glass that allows you to see what others are doing, helping you make informed decisions that can lead to increased profits and better customer engagement.
Q2: How does the structure of a website affect the effectiveness of data scraping?
A2: The structure of a website is crucial for data scraping success. Websites that are well-organized with clear HTML tags and a consistent layout make it easier for scraping tools to extract information. If a website has a complex structure with dynamic content, irregular HTML, or frequent changes, it can be a nightmare for scrapers. Think of it like trying to find your way through a messy maze versus a neatly laid-out street map. The easier it is to navigate, the more efficient the scraping process will be!
Q3: Can you explain what a “crawlable” website means?
A3: Absolutely! A crawlable website is one that allows search engine bots and scraping tools to easily navigate through its pages. This means it has a logical hierarchy, uses proper internal linking, and avoids excessive use of JavaScript to load content. If a website is not crawlable, it’s like putting up a “Do Not Enter” sign for data scrapers. As a result, businesses might miss out on crucial data that could inform their strategies.
Q4: What role do HTML tags and class names play in data scraping?
A4: HTML tags and class names are the backbone of how data is organized on a webpage. Well-defined tags (like
) help scrapers identify where to look for specific data. If a website uses clear and consistent class names, it simplifies the scraping process, making it more efficient and less prone to errors. If the tags are inconsistent or lack structure, scrapers can end up with jumbled information, which can lead to misguided business decisions. It’s all about clarity and consistency!
Q5: What strategies can businesses implement to enhance their website for data scraping?
A5: To optimize a website for data scraping, businesses should:
- Ensure a logical site structure with clear navigation.
- Use semantic HTML markup to define content meaningfully.
- Avoid excessive reliance on JavaScript for loading critical data.
- Regularly audit the site to ensure that any changes do not interfere with scraping tools.
- Create an API that provides structured data, making it easier for legitimate scrapers to access information without hassle.
By following these strategies, businesses can not only enhance their data scraping efforts but also improve user experience and SEO performance.
Q6: Are there any ethical considerations when it comes to data scraping?
A6: Absolutely! While data scraping can provide valuable insights, it’s essential to approach it ethically. Always check a website’s robots.txt file to see if scraping is allowed, and respect the site’s terms of service. Data scraping should be conducted transparently and responsibly, ensuring that it doesn’t disrupt the normal functioning of websites or infringe on user privacy. Ethical scraping builds trust and can lead to valuable partnerships down the line.
Q7: How can businesses leverage the information obtained from successful data scraping projects?
A7: The data obtained from scraping can be a goldmine for businesses. By analyzing this information, companies can identify emerging trends, understand customer preferences, and monitor competitor strategies. This helps in making data-driven decisions, refining marketing strategies, and ultimately leading to higher conversion rates. In short, effective data scraping transforms raw data into actionable insights, giving businesses a competitive edge in their respective markets.
Final Thoughts: Understanding how website structures impact data scraping can make a world of difference in your scraping projects. By focusing on optimization and ethical considerations, businesses can harness the full potential of data scraping to drive success and growth. So, take a moment to assess your website – it might just be the key to unlocking untapped potential!
Insights and Conclusions
the structure of a website can significantly hinge on the success of your data scraping endeavors. As we’ve explored, the way a site is organized—its HTML hierarchy, URL patterns, and even its loading times—can either facilitate a smooth scraping process or pose daunting challenges. By understanding these elements and how they interact with your scraping tools, you can streamline your projects, save valuable time, and ultimately extract the insights you need more effectively.
So, as you embark on your next data scraping journey, take a moment to analyze the architecture of the website you’re targeting. Is it user-friendly? Are the data points you need easily accessible? By being mindful of these factors, you not only enhance your scraping efficiency but also position yourself for greater success.
Remember, a well-planned approach to website structure can turn a potentially frustrating task into a rewarding experience. Don’t overlook this crucial aspect—your future projects will thank you! Dive in, keep experimenting, and let the data flow!

Post navigation
